
Tartalom
Forrás: Kran77 / Dreamstime.com
Elvitel:
A mélyreható tanulási modellek megtanítják a számítógépeket önálló gondolkodásra, nagyon jó és érdekes eredményekkel.
A mély tanulást egyre több területen és iparágban alkalmazzák. A sofőr nélküli autóktól a Go játékig és a képek zenéjének generálásáig minden nap megjelennek új, mélyreható tanulási modellek. Itt áttekintjük számos népszerű mély tanulási modellt. A tudósok és a fejlesztők ezeket a modelleket veszik igénybe, és új és kreatív módon módosítják őket. Reméljük, hogy ez a kirakat ösztönözheti Önt, hogy megnézze, mi lehetséges. (Ha többet szeretne megtudni a mesterséges intelligencia fejlődéséről, olvassa el: Képes-e a számítógépek utánozni az emberi agyat?)
Neurális stílus
Nem javíthatja a programozási képességeit, ha senki sem törődik a szoftver minőségével.
Neurális mesemondó

A Neural Storyteller egy olyan modell, amely egy kép megkapásakor romantikus történetet hozhat létre a képről. Ez egy szórakoztató játék, és mégis el tudja képzelni a jövőt, és megnézheti az irányt, ahova ezek a mesterséges intelligencia modellek mozognak.

A fenti funkció a "stílusváltó" művelet, amely lehetővé teszi a modell számára, hogy a szabványos képaláírásokat átkerülje a regények történetének stílusára. A stílusváltást az "A művészi stílus neurális algoritmusa" ihlette.
Adat
Két fő adatforrás van, amelyet ebben a modellben használnak. Az MSCOCO a Microsoft adatkészlete, amely körülbelül 300 000 képet tartalmaz, mindegyik kép öt feliratot tartalmaz. Az MSCOCO az egyetlen felhasznált felügyelt adat, azaz az egyetlen adat, ahol az embereknek be kellett menniük, és kifejezetten ki kellett írni minden egyes képaláírást.
Az előre-továbbított neurális hálózat egyik fő korlátozása az, hogy nincs memóriája. Minden előrejelzés független a korábbi számításoktól, mintha ez lenne az első és egyetlen előrejelzés, amelyet a hálózat valaha készített. De sok feladathoz, például egy mondat vagy bekezdés fordításához, a bemeneteknek egymást követő és egymással összefüggő adatokból kell állniuk. Például nehéz lenne egy mondatban egyetlen szót értelmezni anélkül, hogy a környező szavak biztosítanák.
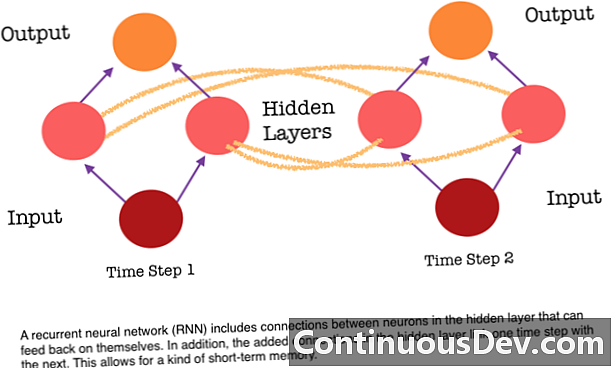
Az RNN-k eltérőek, mivel újabb összeköttetést adnak a neuronok között. Ezek a kapcsolatok lehetővé teszik a rejtett rétegben lévő neuronok általi aktivációkat, hogy visszatérjenek magukba a sorozat következő lépésében. Más szavakkal: egy rejtett réteg minden lépésben aktiválást kap az alatta lévõ rétegbõl és a sorozat elõzõ lépésébõl is. Ez a struktúra lényegében visszatérő ideghálózatok memóriáját adja. Tehát az RNN az objektumok felderítésének feladataira támaszkodhat a korábbi kutyák osztályozása alapján, hogy meg tudja határozni, hogy az aktuális kép kutya-e.
Char-RNN TED
A rejtett réteg rugalmas szerkezete lehetővé teszi az RNN-k számára, hogy nagyon jóak legyenek karakterszintű nyelvi modellekhez. A Char RNN, amelyet eredetileg Andrej Karpathy készített, egy olyan modell, amely egy fájlt vesz bemenetként, és kiképezi az RNN-t, hogy megtanulja megjósolni a sorozat következő karakterét. Az RNN karakterenként generálhat, amely úgy néz ki, mint az eredeti edzési adatok. Demót tanítottak különböző TED-beszélgetések átirataival. Helyezze be a modellbe egy vagy több kulcsszót, és ez létrehoz egy áttekintést a kulcsszóról / kulcsszavakról a TED Talk hangjával / stílusával.
Következtetés
Ezek a modellek új áttöréseket mutatnak a gépi intelligencia területén, amely a mély tanulás eredményeként lehetséges. A mély tanulás azt mutatja, hogy meg tudunk oldani olyan problémákat, amelyeket soha nem tudtunk megoldani, és még nem értük el ezt a fennsíkot. A mély tanulási innováció eredményeként számíthat még néhány izgalmas dologra, például vezetés nélküli autókra a következő néhány évben.